Snorkel is a system for programmatically building and managing training datasets. In Snorkel, users can develop training datasets in hours or days rather than hand-labeling them over weeks or months.
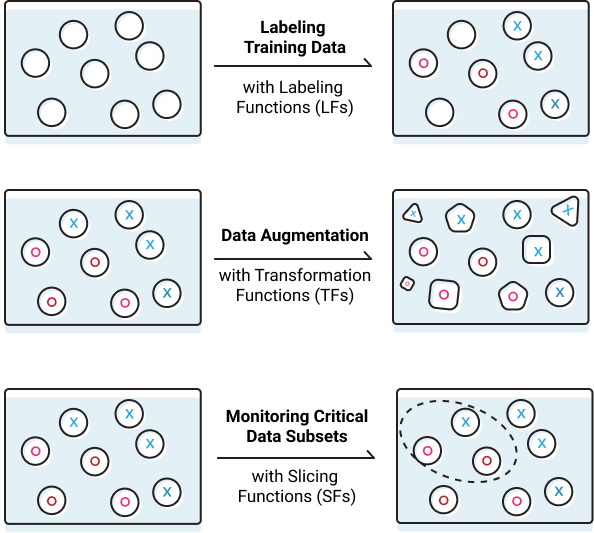
Snorkel currently exposes three key programmatic operations: labeling data, for example using heuristic rules or distant supervision techniques; transforming data, for example rotating or stretching images to perform data augmentation; and slicing data into different critical subsets. Snorkel then automatically models, cleans, and integrates the resulting training data using novel, theoretically-grounded techniques.
Snorkel has been deployed in industry, medicine, science, and government to build new ML applications in a fraction of the time; for more, see tutorials and other resources.
Speed
Label and manage training datasets by writing code to quickly leverage ML for new applications.
Flexibility
Adapt training sets to changing conditions or problem specifications by modifying code, rather that expensive re-labeling.
Privacy
Programmatic labeling strategies can be completely decoupled from sensitive data.
01
Write labeling functions (LFs) to heuristically or noisily label some subset of the training examples. Snorkel then models the quality and correlations of these LFs using novel, theoretically-grounded statistical modeling techniques.
Blog Tutorial VLDB'18 Paper NeurIPS'16 Paper AAAI'19 Paper ICML'19 Paper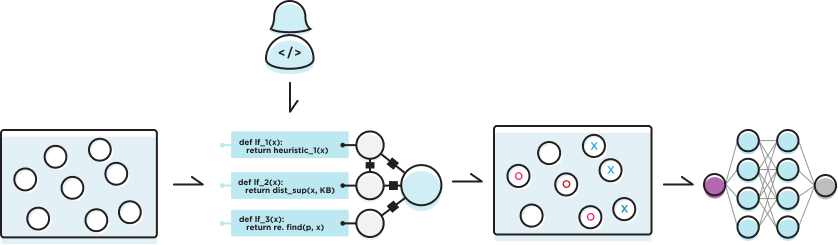
02
Write transformation functions (TFs) to heuristically generate new, modified training examples by transforming existing ones, a strategy often referred to as data augmentation. Rather than requiring users to tune these data augmentation strategies by hand, Snorkel uses data augmentation policies that can be learned automatically.
Blog Tutorial NeurIPS'17 Paper ICML'19 Paper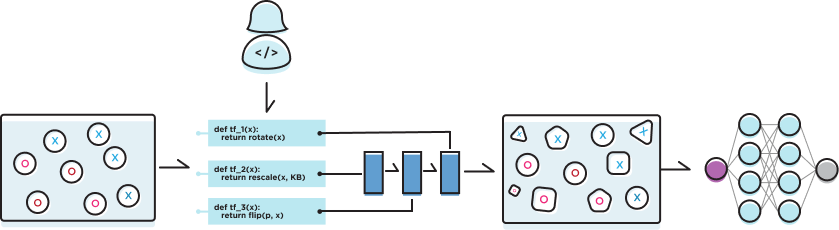
03
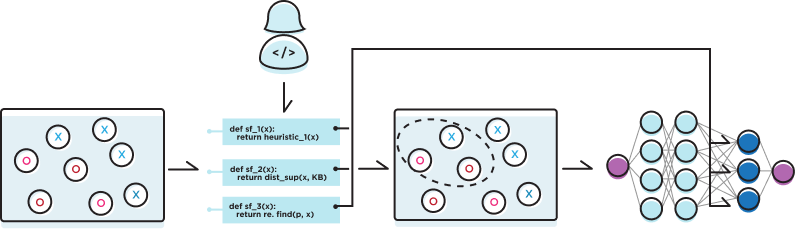
Write slicing functions (SFs) to heuristically identify subsets of the data the model should particularly care about, e.g. have extra representative capacity for, due to their difficulty and/or importance. Snorkel models slices in the style of multi-task learning and an attention-mechanism is then learned over these heads.
Blog Tutorial NeurIPS'19 Paper