

Introducing the New Snorkel
The Snorkel Team
Aug 14, 2019
Snorkel began in 2016 at Stanford as a project that, as suggested by an advisor to his graduate student at the time, “should probably take an afternoon”. That afternoon ended up (happily) being a long one. Over the last few years Snorkel has been deployed in industry (e.g. Google, Intel, IBM), medicine (e.g. Stanford, VA), government, and science; has been the focus of over twenty four machine learning, scientific, and systems publications, including six NeurIPS and ICML papers, two Nature Communications papers, and a “Best Of” VLDB paper; and most rewarding of all, has benefited from the feedback and support of a vibrant and generous user community.
And, it’s far from over. Today we’re excited to announce what we hope will end up being the most impactful step yet: the release of Snorkel v0.9, a modern Python library for programmatically building and managing training datasets.
In this release we:
- Unify and standardize several lines of our research on programmatic training data management and weak supervision, previously scattered across multiple codebases
- Move to a much more modular and data-agnostic configuration of Snorkel that is appropriate for a range of tasks and modalities beyond text information extraction
- Add a new set of revamped and expanded tutorials that we plan to add to regularly
- Attempt to atone for our past research code sins by adding the essential elements of a modern, well-maintained Python library: easy installation, extensive unit and integration testing, typing, documentation, and more.
This is just the beginning — we’re excited for the continued feedback and engagement around this next step for Snorkel!
# New Ways to Build & Manage Training Data
Snorkel is motivated by the observation that as modern machine learning models have become increasingly performant and easy-to-use—but also massively data-hungry—building and managing training datasets has increasingly become the key development bottleneck and limiting factor for actually building real-world ML applications. The goal of Snorkel is to take the operations that practitioners employ over the training data, which are often most critical to ML model success, but also most often relegated to ad hoc and manual processes—e.g. labeling, augmenting, and managing training data—and make them the first-class citizens of a programmatic development process.
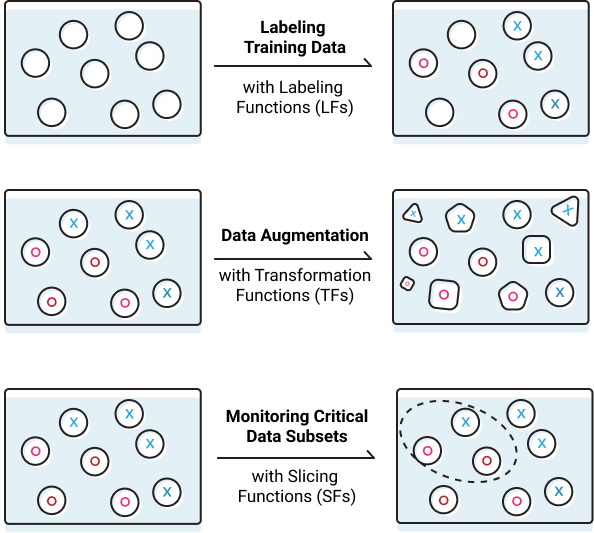
When we started the Snorkel project, we chose to tackle one aspect of this process first: labeling training data. In the new version of Snorkel, we both expand support for this operation, and introduce two new operations: transforming or augmenting data, and slicing or partitioning data. For an overview of how these all fit together in the new version of Snorkel, we recommend checking out the new Getting Started guide!
We now give a brief preview of what these operations look like in the new Snorkel:
# Labeling Functions
The core operator in the mainline Snorkel repo has been the labeling function (LF), which provides an abstracted way to express various heuristic or noisy programmatic labeling strategies.
Snorkel then models and combines these noisy labels into clean confidence-weighted training labels.
For example, in a spam classification problem, a labeling function could employ a regular expression:
@labeling_function()
def lf_regex_check_out(x):
"""Spam comments say 'check out my video', 'check it out', etc."""
return SPAM if re.search(r"check.*out", x.text, flags=re.I) else ABSTAIN
In the new version of Snorkel, we include a new labeling function class that handles flexible preprocessors, memoization, efficient execution over a variety of generic data types at scale, and much more. For more on LFs, see the Getting Started guide and the follow-up Introduction to LFs tutorial.
# Transformation Functions
Another key training data management technique that has emerged over the last several years as especially crucial to model performance is data augmentation, the strategy of creating transformed copies of labeled data points to effectively inject knowledge of invariances into the model. Data augmentation is traditionally done in ad hoc or hand-tuned ways, buried in data loader preprocessing scripts…but it is absolutely critical to model performance. It’s also a perfect fit for the overall philosophy of Snorkel: enable users to program machine learning models via the training data.
In Snorkel, data augmentation is now supported as a first-class citizen, represented by the transformation function (TF), which takes in a data point and returns a transformed copy of it, building on our NeurIPS 2017 work here on automatically learning data augmentation policies. The canonical example of a transformation would be rotating, stretching, or shearing an image (all of which Snorkel supports), but TFs can also be used over text data, for example randomly replacing words with synonyms:
@transformation_function()
def tf_replace_word_with_synonym(x):
"""Replace a random word with a synonym if one exists."""
idx = random.choice(range(len(x.words)))
synonyms = get_synonyms(x.words[idx])
if len(synonyms) > 0:
return substitute_word(x, synonyms[0], idx)
For more on TFs, see the Getting Started guide, and the follow-up Introduction to TFs tutorial.
# Slicing Functions
The newest addition to the Snorkel operator set — also supported in v0.9 — is the slicing function (SF). Slicing functions enable users to heuristically identify slices or subsets of the training dataset that are critical for application performance. Snorkel then uses these SFs to (i) enable monitoring of the model performance over these slices, and (ii) increase performance on the slices by adding representational capacity to whatever model is being used (technical report coming soon!). The syntax for a slicing function is similar to that of a labeling function; for example, if in our spam classification problem it was especially critical to correctly flag potentially malicious links, we could write an SF for this:
@slicing_function()
def short_link(x):
"""Return whether text matches common pattern for shortened ".ly" links."""
return SHORT_LINK if re.search(r"\w+\.ly", x.text) else NOT_SHORT_LINK
For more on SFs, see the Getting Started guide, and the follow-up Introduction to SFs tutorial.
# Upgraded Labeling Pipeline
Handling noisy training labels, e.g. those produced by labeling functions, remains one of the core focuses of Snorkel, and we’re excited to add a set of new capabilities here.
# New Matrix Completion-Style Modeling Approach
One of the core challenges in any type of programmatic or weak supervision is handling noisy sources of labels (e.g. LFs) that may have varying accuracies, correlations, and broadly overlap and conflict with each other. Starting with work in NeurIPS 2016, ICML 2017, and VLDB 2018, Snorkel has handled this challenge using a theoretically-grounded unsupervised generative modeling technique, implemented as a Gibbs-sampling and SGD-based approach.
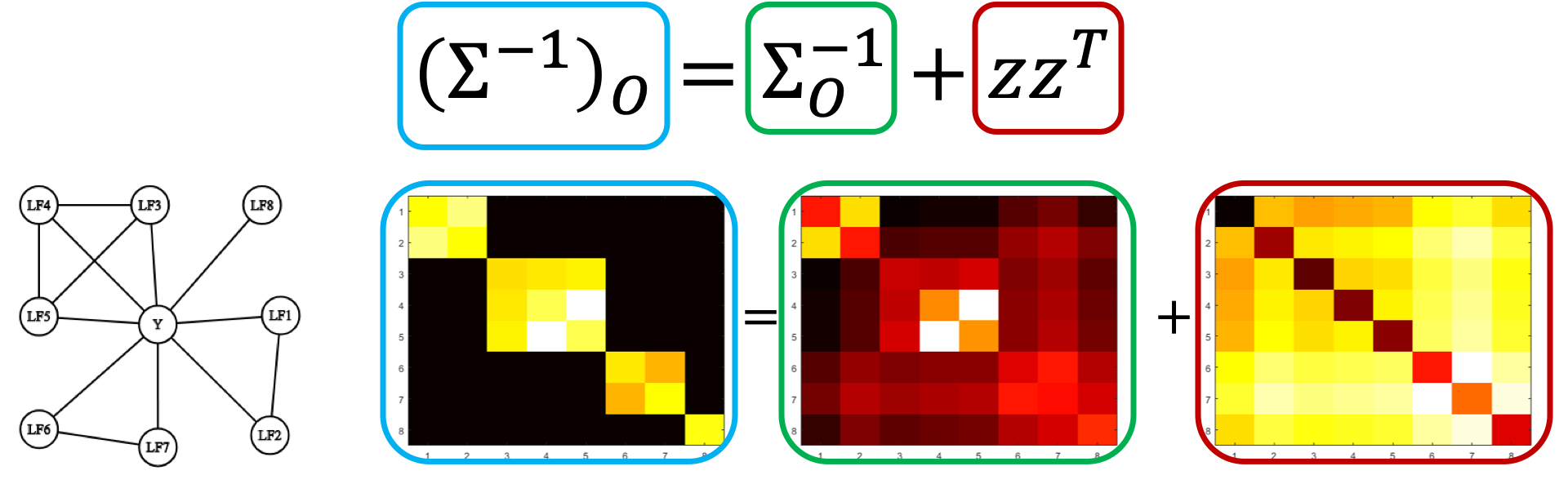
In v0.9, we switch to a new matrix completion-style approach based on our work in AAAI 2019. This new approach leverages the graph-structured sparsity of the inverse generalized covariance matrix of the labeling functions’ outputs to reduce learning their accuracies and correlation strengths to a matrix completion-style problem. This formulation is far more scalable (scaling with the number of labeling functions rather than dataset size!), cleaner to implement more complex models of the labeling process in, and comes with sharper theoretical guarantees.
This approach also enables new techniques for learning the structure of correlations between labeling functions, based on our recent work in ICML 2019. For more, check out the resources page.
# Big Data Operators
Snorkel v0.9 provides native support for applying core operators using
Spark and Dask,
making it easier than ever to work with massive data sets.
Check out our API documentation
for more details.
Natural language processing, in particular, is a common bottleneck in Snorkel workloads.
To faciliate plug-and-play scale-up for text applications, we have special tooling, like the
spark_nlp_labeling_function.
For usage examples, check out the
Drybell tutorial
based on our deployment with Google AI.
# Moving to a Modular, General Purpose Snorkel
Snorkel started out focused on information extraction from text, a use case we continue to support (for example, see the relation extraction tutorial). However, through interactions with users and use cases across many domains, it has become clear that the best way to support the wide range of potential problems and data modalities Snorkel can be applied to — from image and text to video and time series — is to make Snorkel much more modular and data agnostic.
Therefore, one of the changes that will be most noticeable to prior users of Snorkel is that the end-to-end relational data management system for information extraction has now moved to the snorkel-extraction repository, and the new version accepts more generic data objects, e.g. numpy arrays, Pandas and Dask DataFrames, Spark RDDs, etc.
In our experience deploying Snorkel, end-to-end data management systems integrated with Snorkel are still the best way to deploy production applications, but we now leave this as an infrastructure component external to the core Snorkel repo for flexibility.
# Tutorials
One of the most important motivations for us in releasing and maintaining Snorkel as an open source project is to show how programmatic ways of building and managing training data can serve as an efficient, powerful, and accessible new paradigm for building machine learning applications. Given this, maintaining clean, readable, and helpful tutorials is especially important to us. In this new release, we’ve added or re-worked a variety of tutorials on Snorkel:
- Getting Started: A new, quicker (but still end-to-end executable) tour of Snorkel
- Intro Tutorial: A new in-depth tutorial on building applications in Snorkel, focused on a canonical machine learning problem, detecting spam text comments, and split into three parts focusing respectively on labeling functions, transformation functions, and slicing functions
- Hybrid Crowd + Programmatic Labeling: A tour of how Snorkel can be used to combine and integrate both noisy human labels and programmatic labeling strategies
- Multi-Task Learning: A tutorial on Snorkel’s state-of-the-art multi-task learning framework
- Recommender Systems: An example of how to build a simple weakly supervised recommender system with Snorkel
- Information Extraction: A text relation extraction tutorial (previously the Snorkel intro tutorial)
- Visual Relation Detection in Snorkel: A tutorial on classifying visual relationships between objects in an image with Snorkel
We plan to add new tutorials at a regular cadence, and also to accept community-built ones. Please check out our community forum to give us feedback on what tutorials you’d like to see, and also consider submitting your own tutorials as PRs!
# Becoming a Modern Python Library
It’s now easier than ever to get started with, receive support, and contribute to Snorkel. In particular, we’ve adopted best practices around installation, testing, and documentation from lots of well-maintained Python libraries that we use and love.
# Installation
We now support installation in a number of ways, including pip, conda, and installing
from source.
Our tutorials repo also supports Docker installation.
For more details, see the
Snorkel README and
Tutorials README.
# Unit and Integration Testing
Snorkel v0.9 has
over 200 unit tests and integration tests
and coverage tracked on Codecov,
so you can be more confident than ever in the library’s robustness.
We upgraded to tox and
pytest
as our primary testing suite, making it easier for developers to contribute new functionality.
We also added a host of automated tooling to enforce strict code standards
such as static type checking with mypy,
code formatting with black,
and docstring compliance with doctest-plus
and pydocstyle.
# Documentation
Snorkel’s API Documentation on ReadTheDocs
has been overhauled, making it easier to navigate and read.
The documentation is now much more complete (thanks to the tooling listed above and
several documentation sprints) and rebuilds automatically on pushes to master,
so you’ll always be able to find information on the latest features.
# Looking Ahead
We’re excited to build on this release and maintain a regular cadence of new features, tutorials, and integrations. Examples of upcoming additions that we’re excited about include further integrations with modern ML platforms, including TFX and Ludwig; various new tutorials, including a cross-modal weak supervision tutorial based on some of our recent work in the medical imaging and monitoring domain; further data augmentation features around automated policy learning (porting from our NeurIPS 2017 codebase) and new augmentation deployment form factors; and much more!
Much of the above will be guided by community feedback, so please check out our community forum, mailing list, and Github Issues page to give us feedback on what you’d be most excited to see next! We’re looking forward to continuing and deepening our collaboration with the Snorkel community as we further develop and extend this new paradigm for interacting with machine learning through training data, and thank everyone in advance for your feedback and support!